Scrapy + Splash で競馬予想のスクレイピング
目的
前回 Scrapyチュートリアルを試してみたので、今回はnetkeiba.comから競馬予測家の予想コメントを集めてみようと思う。
netkeiba.comのデータ構造の確認
Scrapy shellでnetkeiba.comのデータ構造を見ながら、欲しいデータを抽出する。
まずはレース一覧のページにアクセスして、各レースのURLを抽出する。
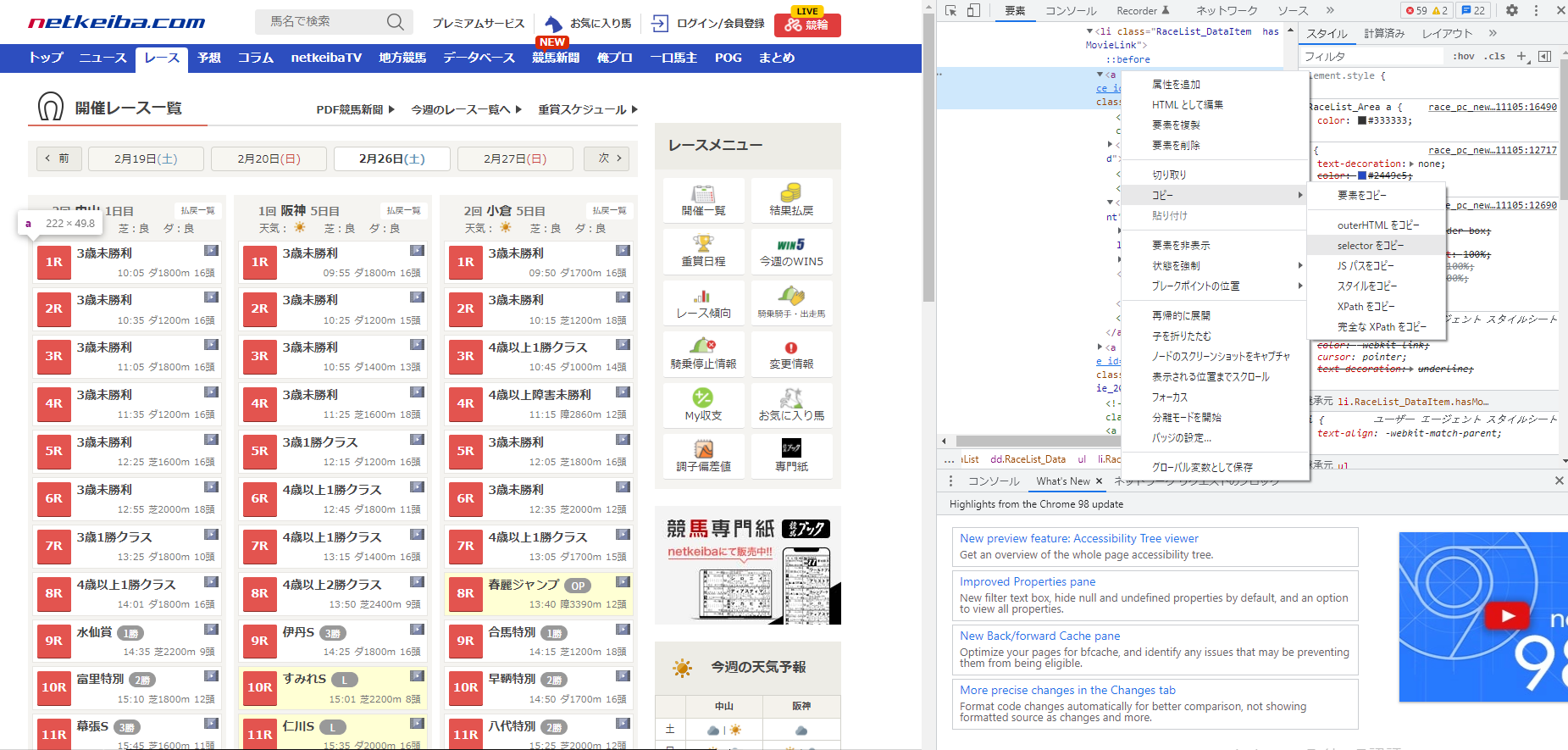
このときChromeの開発者ツールを利用して、欲しい要素のCSSセレクタをコピーすると便利。
開発者ツール左上の「ページ内要素を選択して検査」を押して、マウスカーソルをページ要素に合わせるとハイライトしてくれる。

欲しい要素を見つけたら、「右クリック > コピー > selectorをコピー」でCSSセレクタをコピーできる。
上でコピーしたCSSセレクタを使って、レースページへのURLを抽出してみる。
空のリストが返ってきており、うまく抽出できなかった。
$ scrapy shell "https://race.netkeiba.com/top/race_list.html?kaisai_date=20220226&kaisai_id=2022100205"
In [1]: response.css('#RaceTopRace > div > dl:nth-child(1) > dd > ul > li:nth-child(1) > a:nth-child(1)')
Out[1]: []原因を調べてみると、ページコンテンツがJavaScriptで動的に生成されているためだった。
Scrapyは静的なページコンテンツは抽出できるが、ページアクセス後にJavaScriptで動的に生成されるコンテンツは抽出できない。
この動的コンテンツを抽出するためにはSplashを使うとよいらしい。
Splash
SplashはJavaScriptレンダリングサービスで、HTTP APIをもった軽量なWebブラウザである。
ScrapyとSplashを組み合わせて、JavaScriptで描画されるのコンテンツを含めてデータ抽出することができる。
下記コマンドでscrapy-splashをインストールして、splashコンテナを立ち上げる。
$ pip install scrapy-splash
$ docker run -p 8050:8050 scrapinghub/splash次に、別のターミナルを開いてScrapy shellを起動する。
このとき、アクセス対象のURLをクエリストリングに含めて、splashコンテナにアクセスする。http://localhost:8050/render.html?url={アクセス対象のURL}
これで動的なコンテンツに対しても、いろいろなセレクタを試すことができる。
$ scrapy shell 'http://localhost:8050/render.html?url=https://race.netkeiba.com/top/race_list.html?kaisai_date=20220226&kaisai_id=2022100205'
In [1]: response.css('#RaceTopRace > div > dl:nth-child(1) > dd > ul > li:nth-child(1) > a:nth-child(1)')
Out[1]: [<Selector xpath="descendant-or-self::*[@id = 'RaceTopRace']/div/dl[count(preceding-sibling::*) = 0]/dd/ul/li[count(preceding-sibling::*) = 0]/a[count(preceding-sibling::*) = 0]" data='<a href="../race/result.html?race_id=...'>]SplashをSpiderに組み込む
Splashのドキュメントを読みながら、Spiderに組み込む。
まずは必要な設定設定を追加する。
settings.pyにSplashサーバーのアドレスを追加する。
SPLASH_URL = 'http://192.168.59.103:8050'settings.pyのDOWNLOADER_MIDDLEWARESにSplashMiddlewareを追加し、HttpCompressionMiddlewareの優先度を変更する。
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}settings.pyのSPIDER_MIDDLEWARESにSplashDeduplicateArgsMiddlewareを追加する。
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}DUPEFILTER_CLASSを追加する。
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'- Scrapy HTTP cacheを利用する場合には、scrapy-splashにある
scrapy.contrib.httpcache.FilesystemCacheStorageのサブクラスを追加する。
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'次にscrapy_splash.SplashRequestを使った簡単なRequestの作り方を見てみる。
yield SplashRequest(url, self.parse_result,
args={
# optional; Splash HTTP APIに渡すパラメタを指定する
'wait': 0.5,
# 'http_method'はPOSTする場合は'POST'をセットする
# 'body'はPOSTする場合にrequest bodyをセットする
},
endpoint='render.json', # optional; デフォルトは render.html
splash_url='<url>', # optional; SPLASH_URLを上書きする場合に使用する
slot_policy=scrapy_splash.SlotPolicy.PER_DOMAIN, # optional
)Spider実装
netkeiba.comのクローラーを実装してみる。
Spiderクラスのひな型を作成してくれるコマンドがあったので、試してみる。
$ scrapy genspider net_keiba_comment race.netkeiba.com
$ ls
net_keiba_comment.pyこんな感じで作成された。
これをベースに実装していく。
import scrapy
class NetKeibaCommentSpider(scrapy.Spider):
name = 'net_keiba_comment'
allowed_domains = ['race.netkeiba.com']
start_urls = ['http://race.netkeiba.com/']
def parse(self, response):
pass
レース一覧から各レースのIDを抽出して、各レース予測のページをめぐっていく。
下記コードは2022/02/26のレースを対象としているが、日付の部分を変更すれば他日程のレースもとれるはず。
import scrapy
from scrapy_splash import SplashRequest
import scrapy_splash
import re
class NetKeibaCommentSpider(scrapy.Spider):
name = 'net_keiba_comment'
allowed_domains = ['race.netkeiba.com']
def start_requests(self):
urls = ['https://race.netkeiba.com/top/race_list.html?kaisai_date=20220226']
for url in urls:
yield SplashRequest(url, self.parse,
args={
'wait': 5,
}
)
def parse(self, response):
links = response.css('#RaceTopRace > div > dl > dd > ul > li > a:nth-child(1)::attr(href)')
for link in links:
# レースID抽出
race_id = re.findall('race_id=(.+?)&', link.get())[0]
url = f'https://race.netkeiba.com/yoso/yoso_pro_opinion_list.html?race_id={race_id}&rf=shutuba_submenu'
yield SplashRequest(url, self.parse_yoso,
args={
'wait': 5,
}
)
def parse_yoso(self, response):
link = response.css('#navi_shutuba > a::attr(href)')
race_id = re.findall('race_id=(.+?)&', link.get())[0]
sections = response.css('#page > div.RaceColumn02 > section > section')
for section in sections:
kenkai = section.css('div.YosokaKenkaiBar01.fc > div > h2::text').get()
if kenkai is None:
continue
elif 'コンピューター' in kenkai:
continue
elif '見解' in kenkai:
author = re.findall('(.+?)の見解', kenkai)[0]
raw_str = section.css('div.YosoKenkaiTxtBox > div').get()
comment_str = re.sub('(<div.*?>)|(</div>)|(<a.*?>)|(</a>)', '', raw_str)
yield {
'race_id': race_id,
'author': author,
'comment': comment_str,
}
このSpiderを実行すれば、レースID, 予測家名, コメントが抽出できる。
$ scrapy crawl net_keiba_comment -O comment.csvまとめ
Scrapy+SplashでJavaScriptで動的に描画されるページをクローリングした。
今回取得した予想家のコメントデータを利用して、競馬予測の着眼点を洗い出していきたいと思う。